
skipfish 說明
用來偵測 網站漏洞,... 並非使用常見漏洞偵測方式
sudo apt autoremove
sudo apt-get install skipfish
例如: skipfish -o /usr/bin/temp/ https://tw.yahoo.com


https://code.google.com/p/skipfish/
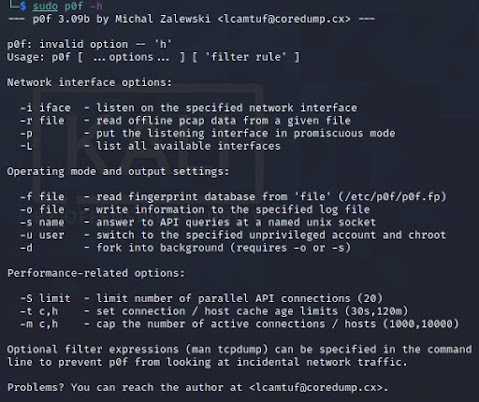
sudo skipfish -h 1 ⨯
skipfish web application scanner - version 2.10b
Usage: skipfish [ options ... ] -W wordlist -o output_dir start_url [ start_url2 ... ]
Authentication and access options:
-A user:pass - use specified HTTP authentication credentials
-F host=IP - pretend that 'host' resolves to 'IP'
-C name=val - append a custom cookie to all requests
-H name=val - append a custom HTTP header to all requests
-b (i|f|p) - use headers consistent with MSIE / Firefox / iPhone
-N - do not accept any new cookies
--auth-form url - form authentication URL
--auth-user user - form authentication user
--auth-pass pass - form authentication password
--auth-verify-url - URL for in-session detection
Crawl scope options:
-d max_depth - maximum crawl tree depth (16)
-c max_child - maximum children to index per node (512)
-x max_desc - maximum descendants to index per branch (8192)
-r r_limit - max total number of requests to send (100000000)
-p crawl% - node and link crawl probability (100%)
-q hex - repeat probabilistic scan with given seed
-I string - only follow URLs matching 'string'
-X string - exclude URLs matching 'string'
-K string - do not fuzz parameters named 'string'
-D domain - crawl cross-site links to another domain
-B domain - trust, but do not crawl, another domain
-Z - do not descend into 5xx locations
-O - do not submit any forms
-P - do not parse HTML, etc, to find new links
Reporting options:
-o dir - write output to specified directory (required)
-M - log warnings about mixed content / non-SSL passwords
-E - log all HTTP/1.0 / HTTP/1.1 caching intent mismatches
-U - log all external URLs and e-mails seen
-Q - completely suppress duplicate nodes in reports
-u - be quiet, disable realtime progress stats
-v - enable runtime logging (to stderr)
Dictionary management options:
-W wordlist - use a specified read-write wordlist (required)
-S wordlist - load a supplemental read-only wordlist
-L - do not auto-learn new keywords for the site
-Y - do not fuzz extensions in directory brute-force
-R age - purge words hit more than 'age' scans ago
-T name=val - add new form auto-fill rule
-G max_guess - maximum number of keyword guesses to keep (256)
-z sigfile - load signatures from this file
Performance settings:
-g max_conn - max simultaneous TCP connections, global (40)
-m host_conn - max simultaneous connections, per target IP (10)
-f max_fail - max number of consecutive HTTP errors (100)
-t req_tmout - total request response timeout (20 s)
-w rw_tmout - individual network I/O timeout (10 s)
-i idle_tmout - timeout on idle HTTP connections (10 s)
-s s_limit - response size limit (400000 B)
-e - do not keep binary responses for reporting
Other settings:
-l max_req - max requests per second (0.000000)
-k duration - stop scanning after the given duration h:m:s
--config file - load the specified configuration file
Send comments and complaints to <heinenn@google.com>.

留言
張貼留言